Непрерывная Интеграция
Использование COBOL калечит разум; исходя из этого, обучение этому языку должно быть признано уголовно наказуемым преступлением.
--Эдсгер Дейкстра
Непрерывная интеграция (CI) жизненно необходима для масштабирования бережливой и гибкой разработки ПО:
Мы пришли к выводу, что нет никаких причин, по которым процессы непрерывной интеграции и автоматической сборки не будут масштабироваться на команды любого размера. На самом деле … [процессы] становятся более важными, чем когда-либо. Magennis07
С помощью CI разработчики постепенно “выращивают” стабильную систему, работая небольшими порциями и короткими циклами. Это позволяет командам работать над общим кодом, улучшает его качество и повышает прозрачность разработки.
Существует ряд заблуждений о CI. На первый взгляд это кажется простой концепцией, но на практике это не так. Попробуем избавиться от одного из частых заблуждений: Непрерывная Интеграция это не автоматизация сборки и запуск тестов.
Классическая статья о CI постулирует:
Непрерывная интеграция - это практика разработки программного обеспечения, в которой участники команды часто выполняют интеграцию своих изменений. Как правило, каждый участник выполняет интеграцию как минимум раз в день, и в итоге достигается такой режим работы, при котором интеграция выполняется несколько раз в день. Каждая интеграция проверяется путём автоматической сборки (включающей тестирование), что позволяет находить ошибки интеграции как можно скорее.
Практики непрерывной интеграции
Непрерывная интеграция - это
- практика разработки, которая…
- помогает держать систему в рабочем состоянии
- приветствует небольшие изменения
- способствует “выращиванию” системы
- проводится по крайней мере ежедневно
- исполняется на основной ветке (master, trunk)
- поддерживается CI-системами
- c большим количеством автотестов
Практика разработки
Слишком часто дискуссии о CI касаются инструментов автоматизации. Хотя инструменты и важны, но CI по своей сути является практикой разработки. Оуэн Роджерс, один из первых создателей CruiseControl.NET1, пишет:
Непрерывная интеграция - это практика, и речь идёт о том, что люди делают, а не о том, какие инструменты они используют. Когда проект начинает масштабироваться, легко попасть в ловушку, думая, что команда практикует непрерывную интеграцию только потому, что все инструменты настроены и работают. Если разработчики не взяли себе за правило регулярно интегрировать свои изменения или поддерживать интеграционную среду в рабочем состоянии, то они не практикуют непрерывную интеграцию. И точка. [Rogers04]
Разбиение изменений на небольшие порции, как минимум их ежедневная интеграция, и дисциплина не ломать сборку - всё это выполняется каждым разработчиком индивидуально. Для этого ему нужен навык работы с небольшими инкрементами и постоянной синхронизацией своей собственной копии системы (или её части) с общей версией.
Внедрение CI требует изменения поведения людей. Мы работали в нескольких крупных продуктах с отлично автоматизированной сборкой, но разработчики не часто интегрировали свой код. Хуже того, заповедь “не убий сборку” активно насаждалась в том числе и через позор ломавших её людей. Как вы думаете, к какому результату это привело? Разработчики стали откладывать интеграцию из-за страха что-то сломать. Несмотря на их превосходную всегда зелёную (всегда проходящую) автоматизированную сборку, они делают вещи, прямо противоположные практике CI.
Помогает разработка через тестирование (TDD) с постоянным рефакторингом. Когда разработчик пишет свой код начиная с модульного теста, он гарантирует, что его локальная копия всегда работает. Все тесты должны проходить всё время. Теоретически, он может интегрировать свой код каждый цикл TDD (около десяти минут2), но на практике достаточно это делать после пары циклов.
CI для больших продуктов сложна именно потому, что это практика разработки. Если бы речь шла только об инструментах автоматизации, вы могли бы просто начать проект по внедрению CI или нанять другую компанию для “инсталляции CI”. Но как практика разработки, CI требует изменения в повседневных привычках всех разработчиков. Для многих людей это сложно, требует времени и постоянных тренировок.
При наличии правильных привычек, разработчики будут…
Держать систему в рабочем состоянии
По аналогии с концептом бережливого производства - Дзидока(jidoka), CI подразумевает всегда держать систему в рабочем состоянии. Если тест не пройден, при локальном прогоне или в CI-инструменте, разработчик исправляет его немедленно и, следовательно, всегда сохраняет систему в рабочем состоянии.
Традиционный последовательный процесс разработки постоянно имеет дезинтегрированную незавершённую работу (work in progress, WIP). Никто не знает, работают ли эти части системы вместе и есть ли дефекты. WIP затрудняет прогнозирование того, когда система сможет быть в готовом состоянии. CI повышает прозрачность, устраняя этот WIP, всегда сохраняя интегрированным все части между собой и обеспечивая контроль и предсказуемость процесса.
Примечание : CI и итеративно-инкрементальная разработка в Scrum имеют одинаковую стратегию. Тем не менее, CI является более конкретной практикой, чем итерация в Scrum. Обе снижают вариативность, неопределённость и риск, работая c небольшими порциями итеративно.
Такая система, находящаяся постоянно в рабочем состоянии, развивается небольшими шагами и создаётся с помощью …

Разработчик Джеймс Шор, автор книги “Искусство гибкой разработки” (The Art of Agile Development) [SW07], подчёркивает, что CI это практика разработки. В своей отличной статье “Непрерывная интеграция за 1 доллар в день” [Shore06], он объясняет, как сделать CI из старого компьютера, резиновой курицы, настольного звонка и автоматизированной сборки. Старый компьютер используется в качестве сервера интеграции. Резиновая курица это маркер интеграции - только тот, у кого она, может интегрировать код. Настольный звонок объявляет об успешной интеграции. Но самый важный шаг в его описании CI состоит в том, чтобы собрать разработчиков в одной комнате и дать им возможность договориться друг с другом: “Отныне наш код в системе контроля версий всегда будет успешно собираться и проходить все тесты”. Резиновая курица не подходит для крупных продуктов. Тем не менее, эта история - хороший способ запомнить, что CI - это практика разработки.
Небольшие изменения
Однажды мы работали с продуктовой группой в Финляндии, которая разрабатывала шлюз. Им нужно было внести изменения в стек протоколов. Они настаивали на том, что его нельзя разделить на небольшие изменения. Они внесли много правок и потратили три месяца, пытаясь заставить систему снова работать. После этого мучительного опыта они согласились никогда не вносить такие большие изменения “за один раз”.
Большие изменения в работающей системе будут её дестабилизировать и разрушать её по-крупному. Чем больше изменение, тем больше времени требуется, чтобы стабилизировать состояние системы.
Избегайте больших изменений. Вместо этого разбивайте каждое изменение на мелкие части - небольшие партии, что является одной из концепций бережливого производства. Каждое изменение будет интегрироваться в систему довольно легко.
С небольшими изменениями вы будете…
“Выращивать” систему
Выращивание, а не строительство - важная смена парадигмы мышления. Фредерик Брукс в своей знаменитой статье No Silver Bullet отражает свой опыт:
Метафора “строительства” исчерпала свою полезность… Если, как я полагаю, концептуальные структуры, которые мы строим сегодня, слишком сложны, чтобы их можно было точно определить заранее, и слишком сложны, чтобы их можно было безошибочно построить, тогда мы должны использовать радикально иной подход… Секрет в том, что это выращено, а не построено… Харлан Миллс предложил, чтобы любая программная система росла путём инкрементальной разработки… Ничто за последнее десятилетие так радикально не изменило мою собственную практику или её эффективность… Воздействие на мораль поражает. Энтузиазм резко возрастает, когда есть работающая система, пусть и самая простая… На каждом этапе процесса всегда есть работающая система. Я нахожу, что команды за четыре месяца могут “вырастить” гораздо более сложные структуры, чем “построить”.
Строительство системы подразумевает строительство отдельных компонентов и, когда они закончены, их совместную сборку. Выращивание же системы подразумевает её развитие и превращение в более крупную систему (см. “Выращивание” против строительства).
Возможно ли это в больших системах с унаследованными кодом? Нас часто спрашивают об этом. Почти в каждом случае ответ - да. Если ваши разработчики или архитекторы не могут этого сделать или утверждают, что это невозможно, воспринимайте это как признак отсутствия у них соответствующих навыков.
Разработчик постоянно интегрирует свою работу, работая над задачей. Он не ждёт завершения своей задачи или всей фичи целиком, чтобы затем “прикрутить” её к системе. Скорее, всякий раз, когда небольшой объём работы может быть интегрирован не ломая сборку, он это делает…
По крайней мере ежедневно
“Непрерывно” это как часто? Как можно чаще! Это может быть ограничено лишь:
- способностью декомпозировать большие изменения
- скоростью интеграции
- скоростью цикла обратной связи
Способностью декомпозировать большие изменения –разбивать большие изменения на более мелкие, сохраняя при этом работоспособность старого функционала - это навык, который необходимо освоить. Чем лучше разработчики умеют декомпозировать, тем чаще они могут интегрироваться. TDD в коротких десятиминутных циклах является отличной техникой для этого.
Скорость интеграции –чем больше времени требуется для интеграции изменений в репозиторий кода, тем реже разработчики будут это делать. Изменения объединяются ради эффективности. На усилия по интеграции влияют накладные расходы (транзакционные издержки), такие как согласования и проверки, необходимые для того, чтобы разработчикам было разрешено интегрироваться. Уменьшите эти накладные расходы или найдите новые креативные способы сделать что-то по-другому. Например, мы работали с продуктовой группой, состоящей из 40 человек, где в сообщении при вливании изменений в основную ветку должен был быть упомянут человек, просмотревший этот код. Как вы думаете, каков был результат? Разработчики собирали все изменения в одну пачку, чтобы сделать обзор кода более “эффективным” и, следовательно, откладывали интеграцию до последнего. Что является локальной оптимизацией. Какое решение? Вместо этого обзор изменений может выполняться на уже интегрированном коде, что не откладывает интеграцию.
Скорость цикла обратной связи –разработчик должен интегрировать только те изменения, которые проходят существующие тесты. В идеале он запускает все тесты перед интеграцией. Чтобы это было возможно, тесты должны выполняться очень быстро. Если они будут медленными, разработчик отложит интеграцию, чтобы “работать более эффективно”. Однако быстро выполнить все тесты непростая задача для больших систем. Поэтому разработчики запускают только часть тестов перед слиянием кода, а CI-система запускает остальные тесты. CI-система действует, как система безопасности, предоставляя разработчику информацию о тех тестах, которые он не проводил. Что происходит, когда CI-система работает медленно? Во-первых, в течение одного цикла произойдёт достаточно много изменений, что увеличит вероятность того, что сборка сломается. Во-вторых, разработчики не будут интегрировать свои изменения в сломанную сборку. Скорее, они будут их накапливать. Наконец, когда сборка исправлена, все разработчики интегрируют свои накопленные изменения, что повышает вероятность повторного нарушения сборки. Поэтому цикл проверки изменений должен быть быстрым. Это уменьшает вероятность поломки билда и улучшает возможности для более частого слияния кода.
Практическое правило для крупных продуктов, переходящих к гибкой или бережливой разработке: все разработчики интегрируются по крайней мере ежедневно. Несмотря на то, что “ежедневная сборка для слабаков” [Jeffries04], интегрироваться ежедневно - это первый шаг для таких продуктов. Вспомните метафору “озеро и скалы”, используемую в бережливом мышлении. Большой камень - отсутствие возможности сделать сборку системы раз в день, учтя изменения всех разработчиков - является достаточно тяжёлым препятствием в больших старых системах с тремя сотнями программистов в четырёх странах. В конце концов, если удалить этот камень, то становятся возможными более короткие циклы обратной связи.
В больших продуктах потребуется время, чтобы научиться разбивать изменения, упростить процесс интеграции и настроить быструю CI-систему, которая работает…
На основной ветке
Разработчики интегрируются на основной или trunk-ветке [BA03]. Разработка в отдельной ветке ведёт к тому, что интеграция с основной веткой откладывается3. Текущее состояние билда не прозрачно, поэтому вы не знаете, работают ли все изменения вместе или нет.
Ветвление во время разработки идёт в разрез с предназначением CI и его следует избегать. Но есть исключения: во-первых, клиенты, возможно, не захотят обновить свой продукт до последней версии, но всё же захотят получать некоторые исправления. Таким образом, необходимы ветки релизов4. Во-вторых, при масштабировании CI-системы может быть полезным иметь быстроживущие ветки, которые автоматически интегрируются в основную - подробнее об этом ниже.
А что если, использовать механизм ветвления для кастомизации? Плохая идея! Управляйте этим при помощи конфигурации или параметризованной сборки вместо использования Системы Управления Конфигурацией ПО (SCM). Однажды мы работали над продуктом для оптимизации сети, разработка которого велась в колоцированной продуктовой группе. Они настаивали на создании веток для различных конфигураций. Разработчики работали над такими отдельными ветками более года. После этого им потребовалось ещё полгода - и много усилий - чтобы слить их в trunk.
Успешная разработка в основной ветке …
Поддерживается CI-системой
Бережливое производство выделяет практику минимизации запасов, которые являются одним из видов потерь. Запасы действуют, как буфер (очередная очередь), в котором скрыты ошибки. Ошибки становятся болезненно видимыми, когда такие буферы удалены - и это хорошо. То же самое происходит, когда все изменения интегрированы непосредственно в основную ветку. Все разработчики часто обновляют свои локальные копии; когда кто-то размещает неработающий код, он виден всем и мешает им.
Люди делают ошибки, это нормально. Страхующая сеть в бережливом производстве может дать сигнал для остановки всей производственной линии и нужна, чтобы обнаруживать такие ошибки как можно раньше. Разработчики исправляют ошибки до того, как это оказало влияние на всех. Такая страхующая сеть, похожая на Андон-систему (систему сигнальных фонарей) в терминологии Тойоты, и есть CI-система.
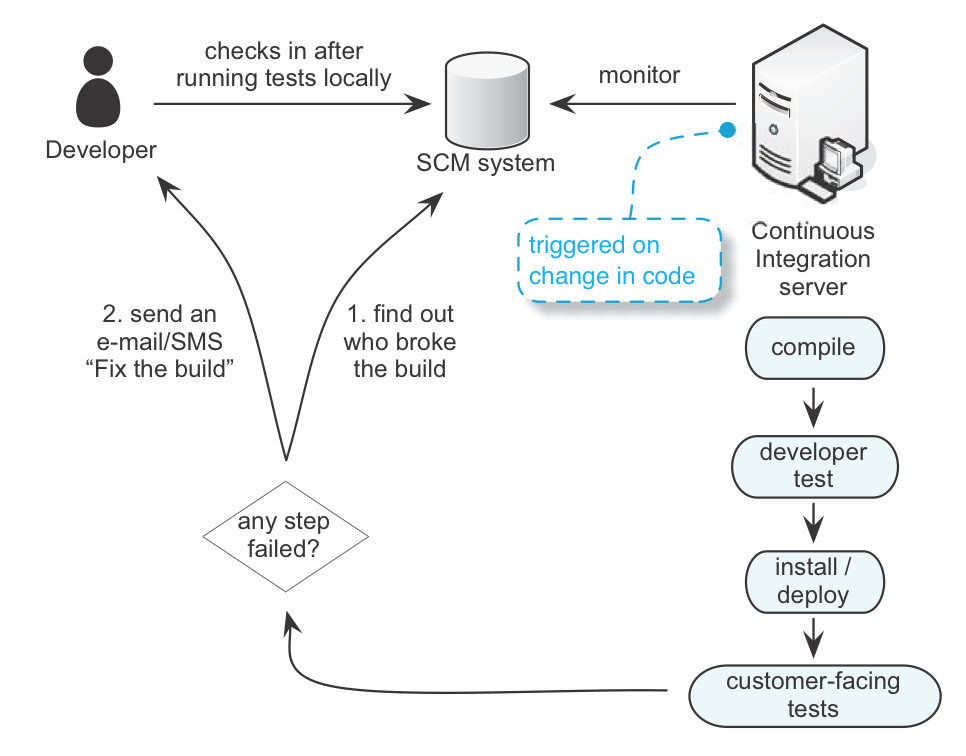
Система CI (см. CI-система) подключена к SCM. Когда разработчик публикует изменения, система CI проверяет весь код, компилирует его, запускает несколько тестов, разворачивает приложение и запускает дополнительные тесты. Всё это происходит быстро. Экстремальное программирование рекомендует это делать каждые десять минут. Если разработчик ломает сборку, система CI выяснит у SCM, кто внёс это изменение. Она посылает ему электронное письмо со словами: “Вы сломали сборку, исправьте её!”. Исправление сломанной сборки является приоритетом номер один, потому что это затрагивает всех.
Для небольшого продукта не составляет труда иметь быструю десятиминутную сборку. Для большого продукта с унаследованным кодом и большой команды это довольно сложная задача. Позже в этой главе рассматриваются несколько методов масштабирования CI-систем…
C большим количеством автотестов
Не так уж и сложно сделать, чтобы CI-система всё компилировала; но это и не особо полезно. Вам необходимо, чтобы в вашей системе CI выполнялось как можно больше тестов. Чем больше автоматических тестов, тем надёжнее ваша страхующая сеть и тем больше уверенность в работе вашей системы.
Для новых продуктов создание автоматизированных тестов не является сложной задачей. Однако многие крупные продукты имеют устаревший код без автоматизированных тестов. Разработчики должны добавить автоматизированные тесты - и это большая работа. Глава об устаревшем коде описывает это.
Масштабирование CI-систем
Во-первых, сборка и тестирование должны быть полностью автоматизированы. У многих продуктовых групп, с которыми мы работали, в сборке присутствовали ручные шаги. Смотрите раздел “Рекомендуем к прочтению” для получения информации об автоматизации сборки.
Препятствия для масштабирования CI-систем связаны с большим количеством людей, производящих большой объём кода и тестов. Во-первых, вероятность разваливания сборки увеличивается, когда всё больше людей публикуют код. Во-вторых, увеличение размера кода приводит к более медленной сборке и, следовательно, к более медленной петле обратной связи CI. Вместе они могут привести к непрерывному отказу сборки (см. Динамика сломанных сборок).
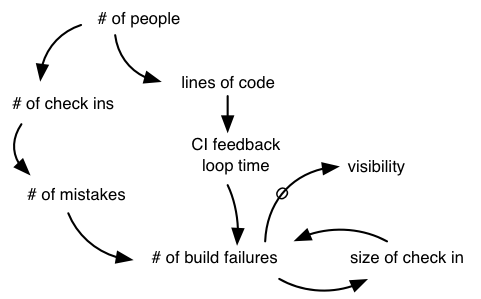
Есть несколько простых решений:
- Ускорить сборку
- Создать многоэтапную CI-систему.
Задача первая: ускорить сборку. Если весь продукт может быть скомпилирован и протестирован в течение одной секунды, то масштабирование будет избыточным. Односекундная сборка пока недоступна для крупных продуктов. Хотя каждое улучшение приближает нас к такой сборке за одну секунду. Дать общие рекомендации по ускорению сборок сложно - это часто зависит от продукта. Некоторые общие решения [Rasmusson04]:
- Увеличьте аппаратные ресурсы
- Распараллельте вычисления
- Поменяйте инструменты
- Собирайте инкрементально
- Разворачивайте инкрементально
- Управляйте зависимостями
- Занимайтесь рефакторингом тестов
Увеличьте аппаратные ресурсы –самый простой способ ускорить сборку - это купить больше “железа”. Добавьте пару дополнительных машин, дополнительную память или ускорьте сетевое соединение, и проблема исчезнет. Обновление существующего оборудования требует лишь инвестиций и минимальных усилий, что делает его самым простым и лучшим выбором. Сборка одного телекоммуникационного продукта ускорилась на 50 процентов за счёт компиляции на RAM-диске - и это потребовало только обновления памяти.
Распараллельте вычисления –связанная с предыдущим пунктом активность, заключается в распараллеливании и разнесении сборки. Это часто требует переработки сценариев сборки, смены или даже создания новых инструментов. Следовательно, требуется больше усилий по сравнению с простым добавлением нового оборудования. Команда крупного телекоммуникационного продукта ускорила сборку их продукта, начав собирать каждый компонент на отдельной машине.
Поменяйте инструменты –обновление инструментов до последней версии или замена медленных на более быстрые ускоряет сборку. Просто пробуя разные компиляторы, мы однажды уменьшили время компиляции на 50 процентов. Наиболее распространённой проблемой, с которой мы сталкиваемся, является медленный IBM Rational ClearCase. Каждый раз, когда продуктовая группа переходила с ClearCase на Subversion - хорошую бесплатную SCM-систему с открытым исходным кодом - они… Во-первых, ускоряли сборку (наши клиенты увидели улучшение на 25-50%); Во-вторых, экономили компании значительные деньги за счёт отказа от лицензий; И в-третьих, улучшали жизнь разработчикам, поскольку ClearCase часто является самым ненавистным инструментом разработки в продуктах, с которыми мы работаем. Некоторые люди обладают не совсем точной информацией и ошибочно утверждают, что Subversion не подходит для разработки крупных продуктов. Но мы видели, что он успешно используется в продуктовых группах с четырьмя сотнями человек, расположенных в разных точках земного шара. По иронии судьбы, так называемые крупномасштабные функции ClearCase, такие как поддержка нескольких площадок, делают реальный CI невозможным, потому что они навязывают “островное” владение кодом.
Собирайте инкрементально –вам нужно только скомпилировать изменившиеся компоненты и запустить соответствующие тесты. Легко в теории - трудно на практике. Зависимости между компонентами, изменения в интерфейсах или несовместимые бинарные файлы - вот некоторые вещи, которые затрудняют компиляцию только изменений. По тем же причинам поиск всех тестов, связанных только с изменённым компонентом, может быть затруднён. Инкрементные сборки редко дают 100-процентную уверенность, и для предотвращения падения сборки всего приложения рекомендуется также делать “чистый” билд ежедневно.
Разворачивайте инкрементально –в больших встраиваемых системах развёртывание или установка программного обеспечения может занимать достаточно большое время. Развёртывание системы в области телекоммуникаций и радиосетей, с которой мы работали, занимало больше часа. Это не является чем-то необычным. Тестирование ускоряется, когда развёртывание выполняется постепенно - развёртываются только изменённые компоненты. Изменения становились доступными только после перезагрузки системы. Однако запуск большой системы занимает много времени, и поэтому некоторые системы обновляются динамически - важная функция в телекоммуникационной и других отраслях, где простои очень дороги. Инкрементное развёртывание - особенно динамическое обновление - требует изменений в системе, что является не самым простым вариантом.
Управляйте зависимостями –неуправляемые зависимости являются частой причиной медленных сборок. Примеры: header-файлы, включающие множество других header-файлов, или несколько циклов ссылок для разрешения циклических ссылочных зависимостей. При разработке мультимедийного продукта мы потратили несколько часов на переупорядочение ссылочных зависимостей - сократив время линкования вдвое. Уменьшение зависимостей ускоряет сборку и, как побочный эффект, улучшает структуру вашего продукта.
- Обратите внимание на ключевую идею
- Улучшение сборки улучшает структуру вашего продукта. Почему? Потому, что плохая структура становится сразу видимой, когда вы пытаетесь сократить время цикла сборки.
Об этом уже говорилось ранее: мощным побочным продуктом сокращения времени цикла является необходимость значительного улучшения процессов и продукта для поддержки коротких циклов и небольших партий.
Занимайтесь рефакторингом тестов –к сожалению, многие разработчики меньше заботятся о коде тестов, чем о продуктивном коде. Каков результат? Плохо структурированный код тестов и их замедление. Однажды мы потратили всего полдня на рефакторинг тестов - и ускорили сборку на 60 процентов! Путём профилирования и рефакторинга тестов вы можете быстро получить подобное преимущество.
Многоэтапная CI-система разбивает сборку и выполняет её в разных циклах обратной связи. На самом низком уровне она имеет очень быструю CI-сборку, содержащую модульные тесты и некоторые функциональные тесты. Когда эта сборка завершается успешно, она запускает сборку более высокого уровня, содержащую более медленные системные тесты. Большие продукты имеют ещё большее количество этапов.
Система CI сравнима с культурой “остановить линию” в Toyota. Когда дефект обнаружен, Toyota останавливает линию, первым приоритетом становится устранение дефекта и его первопричины. А не скрывает ли многоступенчатая CI-система дефекты и не противоречит ли этому принципу бережливого производства? Нет. Принцип “остановить линию” абсолютно необходим, но это не значит, что вы должны слепо остановить всю работу. Даже Toyota этого не делает [LM06a].
Toyota разработала систему, которая позволяет выявлять и устранять проблемы, не обязательно останавливая всю линию. Когда проблема обнаружена и дёргают за сигнальную верёвку, звучит сигнал тревоги и загорается жёлтый индикатор. Линия будет продолжать двигаться до конца текущего этапа производственного процесса - точки “фиксированной остановки”. И линия остановится, когда будет достигнута такая точка, и Андон загорится красным.
Многоэтапная CI-система работает аналогично. Вы выявляете проблему на раннем этапе и решаете её, но не хотите, чтобы она затрагивала всех. Только если проблема окажется действительно серьёзной, вы “остановите линию”.
При построении многоэтапной CI-системы подумайте над:
- сборкой от разработчиков
- фокусом на фичах или компонентах
- автоматическим или ручным “продвижением”
- запуском по событию или расписанию
- количеству этапов
Сборка от разработчиков –разработчики, практикующие CI, должны проверить свои изменения перед слиянием изменений. Следовательно, они должны уметь работать с частью системы, часто с одним из её компонентов, и иметь возможность запускать для него модульные тесты. Примите это во внимание при автоматизации вашей сборки.
Фокус на фичах или компонентах –традиционная многоэтапная система CI построена вокруг компонентов. На самом низком уровне собирается один компонент, на следующем уровне - подсистема, а на самом высоком уровне - весь продукт. Каждая команда, организованная вокруг компонента, заботится только о “своей собственной” CI-системе [AKB04]. Но на каком этапе включить приёмочные тесты более высокого уровня, и как насчёт фиче-команд? Альтернативой является структурирование вашей системы CI как раз вокруг фич. Когда кто-то публикует изменение в коде, все соответствующие CI-системы компонентов запускаются. Теперь тесты выполняются параллельно, но один и тот же компонент компилируется несколько раз.
Одна территориально распределённая продуктовая группа, с которой мы работали, использует два подхода. На более низком уровне CI-система организована вокруг компонентов, а их окончание является триггером для запуска мультифункциональных этапов CI-системы, выполняющих высокоуровневые приёмочные тесты параллельно.
Автоматическое или ручное “продвижение” –подключение всех этапов CI к основной ветке создаёт беспорядок. Когда разработчик делает ошибку, все этапы сборки сразу падают. Система CI более высокого уровня должна запускаться после сигнала о том, что компоненты собраны и готовы для использования. Такой сигнал называется “продвижением” и может быть создан путём маркировки (или тегирования) компонента. “Продвижение” выполнятся автоматически или вручную [Poole08]. При автоматическом продвижении CI-система нижнего уровня “продвигает” компонент после прохождения всех проверок. Избегайте ручного продвижения, при котором команда сама решает, когда компонент “достаточно хорош”, и продвигает его.
Запуск по событию или расписанию –каждая CI-система запускается либо по событию, либо по расписанию. Системы CI низкого уровня всегда запускаются по событию - изменению кода в репозитории. Для систем CI более высокого уровня триггером является либо “продвижение” компонента, либо расписание. Запуск при продвижении быстрее, но для медленных сборок он не стоит дополнительных усилий по настройке и обслуживании. Ежедневная сборка более высокого уровня может быть достаточной для таких ситуаций [Vodde08]. Например, одна распределённая продуктовая группа, с которой мы работали, имела низкоуровневые CI-системы, запускаемые при изменения кодовой базы, а высокоуровневую CI-систему, запускаемую “продвижением”, и ежедневные тесты, выполняемые в течение восьми часов.
Количество этапов - размер и степень “унаследованности” продукта определяют, сколько уровней систем CI необходимо. Общие этапы могут быть следующими:
- быстрый уровень компонентов –очень быстрая низкоуровневая CI-система для получения быстрой обратной связи. Она запускает модульные тесты, рассчитывает покрытие, проводит статический анализ и измеряет цикломатическую сложность кода.
- медленный уровень компонентов –более медленная низкоуровневая CI-система. Она запускает интеграционные или медленные тесты на уровне компонентов.
- уровень проверки стабильности всего продукта –очень быстрая CI-система уровня продукта для получения быстрой обратной связи о стабильности всего продукта. Она запускает быстрые функциональные тесты (smoke-тесты).
- уровень фич –медленная высокоуровневая CI-система. Она запускает функциональные и приёмочные тесты.
- системный уровень –медленная высокоуровневая CI-система. Она запускает системные тесты, которые часто могут занимать несколько часов.
- уровень нагрузочного тестирования –очень медленная CI-система высокого уровня. Она постоянно проводит тесты на стабильность и нагрузку, которые занимают дни, если не недели.
Нам ещё предстоит увидеть все этапы в одном продукте. Большинство продуктов выбирают наиболее важные для них этапы и добавляют остальные только при необходимости. Неоправданно сложная CI-система - это потери.
Пример многоэтапной CI-системы
Иллюстрация “Масштабированная CI-система” показывает пример поэтапной системы CI. В этом примере каждый компонент имеет свою CI-систему, выполняющую модульные тесты, проводит статический анализ и рассчитывает показатели покрытия кода. Успешная сборка “продвигает” компонент и запускает CI-системы уровня фич, выполняющие высокоуровневые тесты. Ежедневная сборка выполняет системные тесты, такие как нагрузка.

CI-система может эффективно поддерживать визуальное управление - один из принципов Бережливого Производства. Когда сборка падает, визуальный сигнал указывает на отказ - Андон-система (в терминологии Toyota). Цель не в том, чтобы менеджеры наказывали разработчика, который сломал сборку; наоборот это инструмент для разработчиков, чтобы они могли видеть статус сборки. Что они будут делать с этой информацией? Изучить, что происходит, или отложить их интеграцию в случае сбоя сборки. Если через некоторое время визуальный сигнал все ещё указывает на сбой, большее количество людей может подключиться к поиску причины сбоя.
Раньше в качестве популярного визуального инструмента использовалась лавовая лампа, подключённая к CI-системе. Зелёная пузырящаяся лавовая лампа указывала на успешную сборку. Но когда сборка не удавалась, красная лавовая лампа начинала пузыриться.
После лавовых ламп люди начали подключить к CI-системам всевозможные визуальные эффекты, такие как рождественские огни, сирены и движущиеся скелеты, которые кричали, когда сборка не удавалась. Хотя пример с простым монитором и веб-страницей красного или зелёного цвета (красно-зелёный экран) менее интересен, но такой способ проще повторить. Красно-зелёные экраны, кажется, стали вездесущими в крупномасштабных CI-системах. В некоторых версиях имеется жёлтый сигнал, указывающий на то, что повреждённая сборка находится в процессе исправления. Простое большое цветовое пятно, видимое на расстоянии, является ключевым элементом, но на дисплее также можно добавить текст или данные диаграмм, таких как продолжительность сборки или покрытие тестами. Информацию можно ограничивать лишь информацией о сборке [Rogers08].


Одно предупреждение, относящееся к визуальному управлению, хорошо сформулировано Джеффри Лайкером [LH08]:
То, что есть визуальное представление, не означает, что есть и визуальный менеджмент. Относительно легко настроить красивую визуализацию. Сложнее всего сделать их “ежедневным движением”. Многие люди, которые посещают заводы Toyota, открыто озвучивают отличие в их подходе. Мы часто слышим комментарии, такие как “Теперь я вижу, что то, что демонстрирует Toyota, на самом деле является ежедневной движущей силой”. Это действительно отличие, и в Toyota могут предложить избавиться от того визуального представления, которое не продвигает ежедневную работу.
В больших продуктах ещё сложнее декомпозировать большие изменения на мелкие. Разработчики иногда хотят реструктурировать или переработать архитектуру своей унаследованной системы и убеждены, что это должно быть сделано в рамках одного большого изменения. Но нам ещё только предстоит увидеть крупный рефакторинг, который нельзя было бы сделать постепенно. Каждый раз, после обсуждения с разработчиками, мы находили способы разделения “должно быть сделано за один раз” рефакторинга [RL06].
Изменения интерфейсов являются распространённой проблемой в больших системах. Многие компоненты используют интерфейс и должны быть изменены, что делает невозможным постепенный переход, верно? Нет, это не так. На самом деле, изменение интерфейса в API является распространённым явлением, и существует известное решение:
Каждый шаг можно сделать самостоятельно и в разное время. Для общедоступных API невозможно выяснить, есть ли ещё пользователи старого интерфейса. Это затрудняет удаление этого интерфейса. Но большинство интерфейсов не являются частью опубликованного API, поэтому вы можете их удалять. Мы видели много продуктов с тремя или четырьмя интерфейсами для обращения к файловой системе или для работы с журналированием, потому что старые так и не были удалены.
Что можно делать, а что не стоит
В предыдущем разделе упоминается, что можно делать, а что не стоит в рамках CI-практики:
Делайте коммиты и интегрируйтесь каждый цикл TDD (например, каждые 5 или 10 минут) - И, как разработчики, мы знаем, что это легко достигается при написании нового кода, но несёт сложности при работе с “грязным” унаследованным кодом.
НЕ ведите разработку в отдельных ветках - если вы используете распределённую систему контроля версий, такую как Git, сливайте изменения в общий “мастер” на общим сервере каждый цикл TDD.
НЕ используйте правило обязательного ревью кода перед слиянием - если вы это сделаете, ваша интеграция будет длиться дольше, создавая проблемы с качеством и множество скрытых дефектов! Вместо этого…
Встройте качество в код для поддержки оптимистичной интеграции - как перейти от пессимистичной политики отложенной интеграции после ревью кода к оптимистической политике ранней интеграции? Развивайте высокий уровень культуры разработки программного обеспечения, TDD-практик и рефакторинга для поддержания чистоты кода, парного или mob-программирования для ревью во время написания кода и автоматических инструментов анализа кода. И если ревью кода все ещё необходимы, делайте их на более медленном цикле небольших партий уже опубликованного кода.
НЕ используйте правило “не ломать сборку”; и НЕ обвиняйте и НЕ стыдите тех, из-за кого она ломается - если вы это сделаете, это усилит в разработчиках страх и отложит интеграцию. И опять же, получите долгую задержку в интеграции со многими скрытыми проблемами. Вместо этого…
Сделайте так, чтобы легко было быстро потерпеть неудачу, остановиться и исправить, а также научиться на ошибках - Создайте быстродействующую CI-систему, которая даёт быструю обратную связь при поломке билда. Устраните барьеры, которые мешают людям практиковать остановку и исправление. Создайте обстановку личной безопасности, где люди могут признавать проблемы и учиться, чтобы совершенствоваться.
Применяйте “остановись и исправь”, когда сборка ломается - “Мы слишком заняты решением проблем, чтобы исправить нашу сломанную сборку”. Нужно ли объяснять это? Не думаю.
Используйте визуальный менеджмент, показывающий состояние сборки - Установите старые ненужные компьютеры и мониторы “везде”, чтобы показывать состояние сборки.
Используйте feature toggles (“переключатели фич”, “рубильники”)
Как и при непрерывной интеграции, feature toggles часто, к сожалению, не рассматриваются, как механизм для поддержки координации и интеграции.
Частая проблема координации и интеграции в больших продуктовых группах состоит в том, что некоторые команды добавляют фичи, которые сразу готовы к использованию, а другие добавляют фичи, которые не готовы к дате выпуска и не должны быть видны. Обычно это происходит потому, что они не обладают достаточной ценностью, чтобы быть минимально полезными. Что делать, вместо того, чтобы откладывать интеграцию, работая в отдельной ветке или не проверяя код?
Используйте feature toggles, которые делают доступными или скрывают фичи в зависимости от настроек конфигурации, и при этом все разработчики и команды постоянно интегрируются. А для масштабирования используйте бесплатный инструмент с открытым исходным кодом, такой как Togglz.
Простым языком feature toggle - это просто условный оператор вокруг кода. А зачем нужен специальный инструмент? Что делают такие инструменты, как Togglz, полезными в контексте масштабирования, так это административные функции, которые они предоставляют для управления переключателями многих фич в различных окружениях, таких как промышленная среда или песочница.
Заключение
С чего начать? Использование CI требует
- изменения поведения разработчиков
- настройки CI-системы
Изменение поведения разработчиков - это самая трудная задача, потому что в больших продуктовых группах много людей. Сосредоточьтесь на TDD - отличный способ разделить большие изменения на более мелкие. Участие тренеров по TDD, которые обучают в парах, является эффективным способом изучения TDD. Но будь терпеливым. TDD - это сложная практика для большинства разработчиков, и обучение требует времени.
Настройка CI-системы CI - большинство продуктов, с которыми мы работали, запускали отдельный проект для построения CI-системы. Это работает, хотя лучшей альтернативой является создание элементов в Бэклоге Продукта и работа над ними существующими фичи-командами. Это создаёт бОльшую прозрачность и чувство владения - разработчики также и пользователи.
Большинство проблем с внедрением CI являются организационными, а не техническими. Во многих продуктах, с которыми мы работали, CI-практика превратилась в организационный беспорядок. В нём участвовали многие традиционные функции и роли: разработчики, менеджеры, тестировщики, инженеры по автоматизации тестирования, скрам-мастера, Agile-коучи, администраторы SCM и сотрудники ИТ. Результатом стали неясные обязанности, обвинения и комитеты (так называемые “руководящие группы”), которые вечно обсуждали, а реальной работой никто не занимался. Каков результат? Прогресса нет. Если это произойдёт, не пытайтесь скрыть организационные проблемы за техническими решениями и не сдавайтесь, потому что “наш продукт слишком сложен для CI”.
Почему бы не сдаться? Потому что каждая продуктовая группа, с которой мы работали, и которая прошла этот путь “удаления больших камней” по отношению к CI, однозначно сочла его чрезвычайно полезным.
Рекомендуем к прочтению
Настоящий текст в описании CI опирается на:
- Extreme Programming Explained , by Kent Beck. Термин CI был впервые упомянут в Экстремальном Программировании.
- Continuous Integration , by Martin Fowler. Наверное, самое лучшее описание CI из существующих.
Рекомендации, относящиеся к автоматизации сборок:
- Managing Projects with GNU Make , by Robert Mecklenburg. При работе с C/C++ вы, вероятно, будете использовать утилиту Make. Эта книга даёт отличный обзор Make, а также рассказывает о ней в крупномасштабной разработке.
- Ant in Action , by Steve Loughran and Erik Hatcher. При работе с Java вы, вероятно, будете использовать Ant. Эта книга посвящена Ant, но охватывает и другие темы. Также рассматривается ещё один популярный инструмент автоматизации сборки - Maven.
- Groovy in Action, by Dierk Koenig, Andrew Glover, Paul King, Guillaume Laforge, Jon Skreet. Groovy - это относительно новый язык программирования с динамической типизацией на основе JVM. Он имеет отличную поддержку автоматизации сборки.
- Pragmatic Project Automation: How to Build, Deploy and Monitor Java Apps , by Mike Clark. Небольшая книга, которая охватывает множество технологий, связанных с автоматизацией сборок в Java-проектах.
- Continuous Integration: Improving Software Quality and Reducing Risk , by Paul Duvall, Steve Matyas, and Andrew Glover. Книга освещает автоматизацию сборки в большей степени, нежели чем практику CI.
CI в крупномасштабной разработке:
- “Scaling Continuous Integration ,” by Owen Rogers (также на сайте: https://exortech.com/blog/wp-content/uploads/2008/05/scaling-ci-3.pdf) в Extreme Programming and Agile Processes in Software Engineering 2004 Conference Proceedings.
Сноски
- CruiseControl.NET - это CI-сервер для платформы for Microsoft .NET.
- Для разработки на Java 10 минут - это слишком много. Для C++ в среднем нормально. Для C, возможно даже мало. 10 минут - среднее время TDD-цикла независимо от языка и платформы.
- Чтобы быть более точным, избегайте веток, которые живут дольше нескольких часов. Работа с ветками становится проще при использовании современных систем контроля версий, таких как Git или Mercurial. Иногда использование быстроживущих веток может быть полезным… но это опасный инструмент, который можно с лёгкостью использовать во вред [Fowler09].
- Совет: Создавайте релизные ветки перед самым выпуском релиза, а не при начале его разработки.
- Это было в статье под названием “Continuous Integration and Automated Builds at Enterprise Scale”, которая раньше была доступна по адресу blog.aspiring-technology.com/file.axd?file=Continuous+Integration+at+Enterprise+Scale.pdf. К сожалению, ссылка перестала работать. Если кто-то знает работающую ссылку на этот документ, дайте знать.
Перевод статьи осуществлён Кротовым Артёмом и Титовым Игорем